Notice
Dreamtonics has released a comprehensive official user manual along with version 1.11.0 of Synthesizer V Studio; this unofficial manual will no longer be maintained. Please visit the Official User Manual for all future updates and information.
Editing Phonemes
Phonemes are the individual components that lyrics and syllables are made up of. Each phoneme represents a specific sound that Synthesizer V Studio is capable of producing (along with transition sounds between each phoneme).
All lyrics entered into notes are automatically converted to phonemes. When rendering the synthesized output, the phonemes ultimately determine the pronunciation and timing.
Info
The default dictionary mappings for each lyric will produce the most likely "correct" pronunciation for the word, however it is rare that human vocalists sing with perfect enunciation, or even that different human vocalists will sing the same lyrics in the same way.
Adjusting phoneme sequences to achieve a desired pronunciation is a normal and expected part of the Synthesizer V Studio workflow.
Available Phonemes
Each language has its own set of phonemes and notations.
A full list of phonemes for each language can be found on the Phoneme Reference page, as well as in Synthesizer V Studio's installation directory.
| Language | Lyrical Notation | Phonetic Notation |
|---|---|---|
| English | Words | Modified Arpabet |
| Japanese | Hiragana, Katakana, Romaji | Romaji-derived symbols |
| Mandarin Chinese | Chinese characters (simplified/traditional), Pinyin | X-SAMPA |
| Cantonese Chinese | Chinese characters (simplified/traditional), Jyutping | X-SAMPA |
| Spanish | Words | X-SAMPA |
Changing a Note's Phonemes
Phonemes are displayed above a note, as well as in the Note Properties panel when the note is selected.
If the text above the note is white, this means the phoneme sequence for the note is automatically being converted from the lyric entered inside the note (either from the active dictionary or by default phoneme conversion).
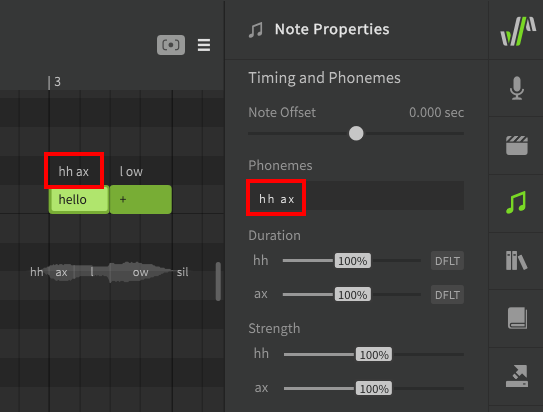
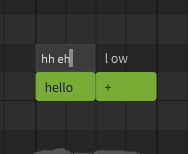
There will be times where the default pronunciation does not match what is desired for your song. For example, hh ax l ow and hh eh l ow are both common pronunciations for the word "hello" depending on the speaker's accent, so the default sequence will inevitably be "incorrect" in some situations.
Double click on the phoneme text above a note to enter a modified phoneme sequence. Press Enter or click outside the note to confirm, or press Esc to cancel the change.
Pressing Tab will confirm the change and advance to the next note, while Ctrl+Tab will move to the previous note.
You can also use the text input in the Note Properties panel instead of double-clicking above the note.
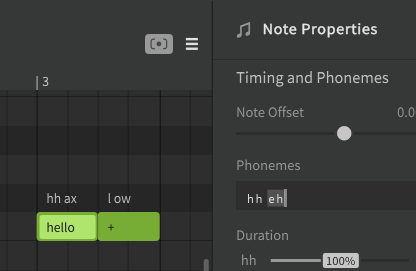
After manually modifying the phoneme sequence, the text above the note will be green instead of white. When a note's phonemes have been entered manually in this way, the lyric inside the note will have no effect on the synthesized output.
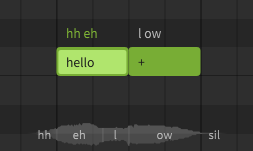
To revert the phoneme sequence to the automatic lyric-based conversion, set the phoneme sequence to an empty value.
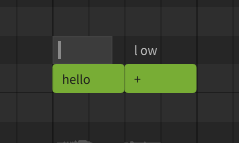
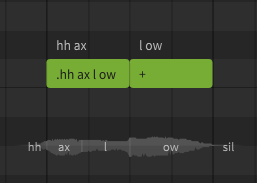
A phoneme sequence can also be entered within a note by prefixing it with a . character. This format is primarily used for backwards compatibility with .s5p project files, but can also be useful when a note only contains a single phoneme.
It is generally best to avoid entering lyrics (or dot-prefixed phoneme sequences) with spaces in them, as this can interfere with the ability to use the Batch Lyric Input dialog, which allocates lyrics to notes based on the spaces between words.
Custom Lyric-to-Phoneme Conversion
If there are many instances of the same word in your project, you may want to override the default phoneme conversion for all instances of that lyric. This can be accomplished by creating a User Dictionary.
Separating Words in Unique Ways
While the + and - characters allow words to span multiple notes on their vowels and syllable boundaries, there may be situations in which you want to separate a note in a more precise manner.
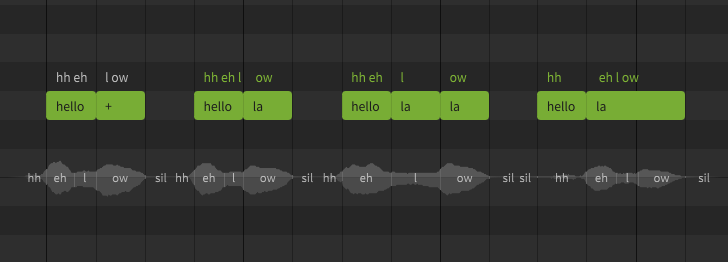
Manually allocating a word's phonemes in different ways can be a useful method of adjusting timing or articulation. Since human vocalists most often perform transitions at vowel and syllable breaks, care should be taken not to create a halting or unnatural sound using this technique.
This example demonstrates the same lyric as above – "hello" – allocated to notes in a variety of ways using manual phoneme entry.
Notice that in the last example, the hh phoneme is no longer treated as a preutterance (which normally occurs before the start of the note) because it is the only phoneme allocated to its respective note.
Keep in mind that if a phoneme sequence has been manually set, the lyric inside the note no longer has any effect on the output.
Special Phoneme Symbols
br (Breath)
Breath notes can be added by entering br as the note's lyric (AI singers only).
It is generally recommended to include breaths as their own notes, however the br symbol can also be used as part of a note's phoneme sequence.
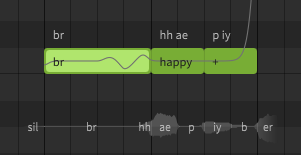
cl (Glottal Stop)
Glottal stops can be added between notes by prefixing the following lyric with a single quote (') or using the cl phoneme. A note containing just a single quote can be used to add a glottal stop at the end of a phrase.
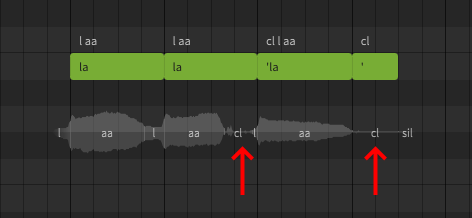
Hard Onsets
While a "glottal stop" is, strictly speaking, the sudden termination of airflow (and the resulting sound), the same symbol can be used in Synthesizer V Studio to create hard onsets, either by using the single quote (') lyric prefix or the cl phoneme at the start of a phrase.
sil (Silence)
The sil symbol will force silence for its duration. In contrast to the glottal stop, which mimics the way humans might suddenly stop or start the airflow, adding silence in this manner can sound more artificial than the default onsets and offsets, because adding it manually restricts the neighboring phoneme duration rather than mimicking a human behavior.
In this example, a small silence note is added to forcibly shorten the preutterance in a case where the leading consonant may be more drawn out than is desired. A similar result can also be achieved by assigning the leading consonant to its own note, which forces the phoneme boundaries to adhere to the note boundaries rather than being considered a preutterance.
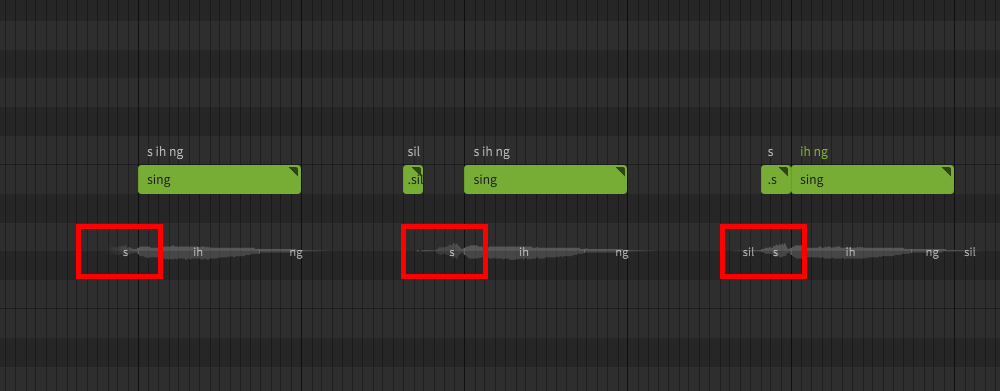
You may also notice sil symbols overlaid on the waveform preview in places where you did not explicitly add them. These silence indicators show the boundaries of the rendered phonemes.
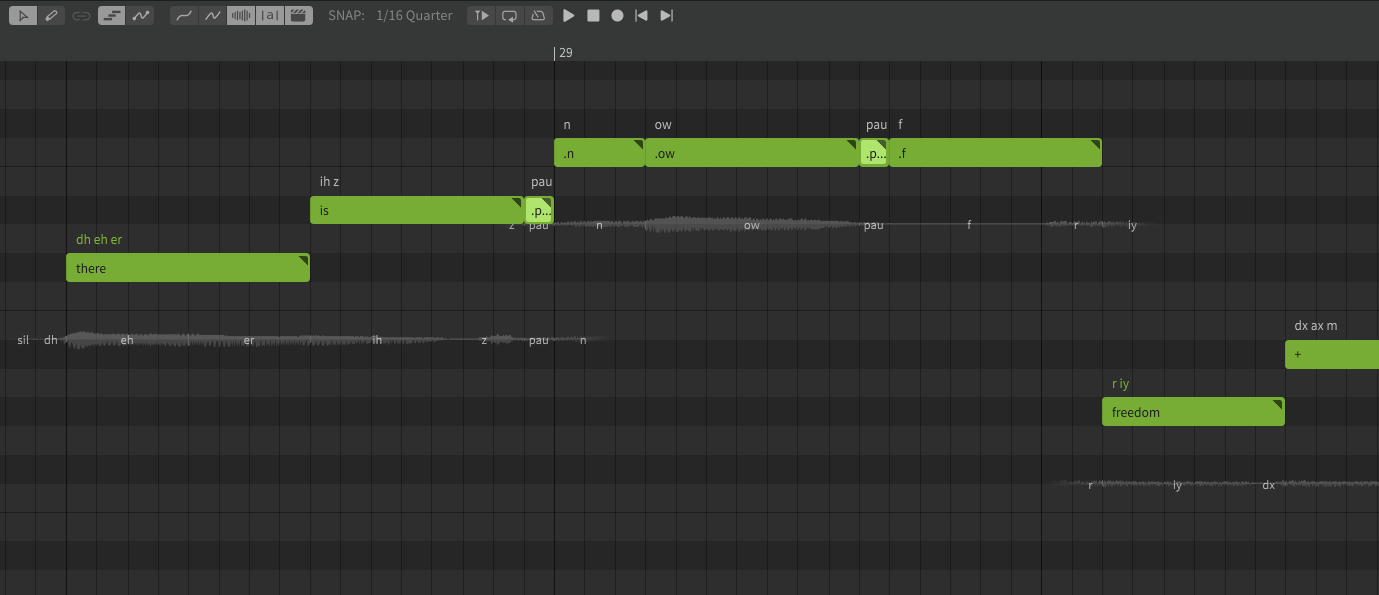
pau (Pause)
The pause symbol allows for smooth transitions between certain phonemes. The exact behavior is highly situational, and will vary based on the selected voice database, as well as which phonemes surround it.
In the example, the phrase "there is (pau) no (pau) freedom" contains a number of phoneme edits to fine-tune the pronunciation and timing, including two small pau notes. These pauses help transition smoothly between the surrounding words without the jarring interruptions that might be caused by a glottal stop, forced silence, or a gap between the notes.
While connected speech can be a valuable tool in creating natural sounding pronunciation, in this case pau is used to prevent the words from blending together, such as where "no freedom" could easily sound like "nof / reedom".
Homographs (different words with identical spelling)
Some English words are spelled the same, but have multiple different pronunciations, even within the same accent or dialect. For example, you might separate (verb) two objects in order to keep them separate (adjective).
In some cases, there will be another word that can be easily subsituted. For example, the default phoneme mapping will interperet "tears" as the ripping of paper, rather than the water that comes from your eyes when you cry. For this scenario, you can easily produce the other phoneme sequence with the word "tiers", which has a different meaning but the desired pronunciation.
In other cases, where there is no simple substitution to be made, it can be helpful to add a dictionary entry for the word with the other pronunciation, or a second phoneme mapping if both pronunciations are needed.
For example, if you need both versions of the word "separate" in your track, you can keep the default verb pronunciation as "separate", while adding the adjective pronunciation as a dictionary entry with a different label like "separate2".
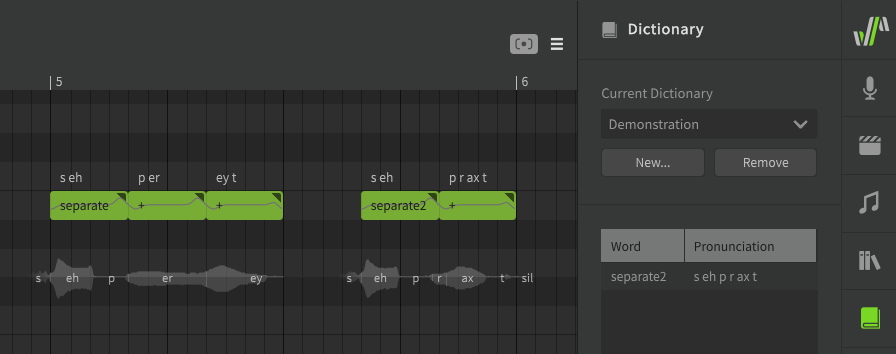
The Word "The"
In Synthesizer V Studio, "the" is a special case. When using the default English phoneme mapping, the phoneme sequence will depend on whether it comes before a consonant or a vowel sound.
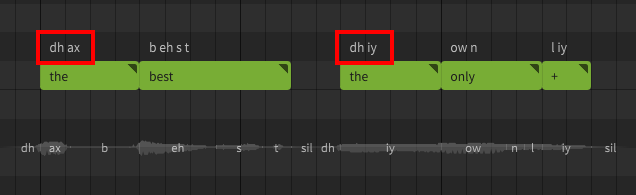
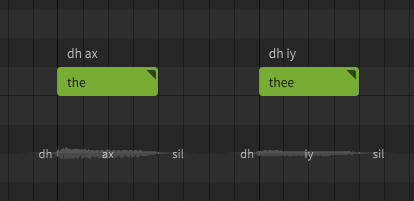
When no word follows, the phoneme sequence will be as though it preceded a consonant. To force the other pronunciation, you can use "thee" as the lyric instead, or modify the phoneme sequence directly.
"Lazy" Pronunciation
People often do not enunciate clearly when singing, using what might be considered "incorrect" pronunciations. Some of the most common phonetic changes to make in Synthesizer V Studio involve replacing over-enunciated words with "lazier" counterparts.
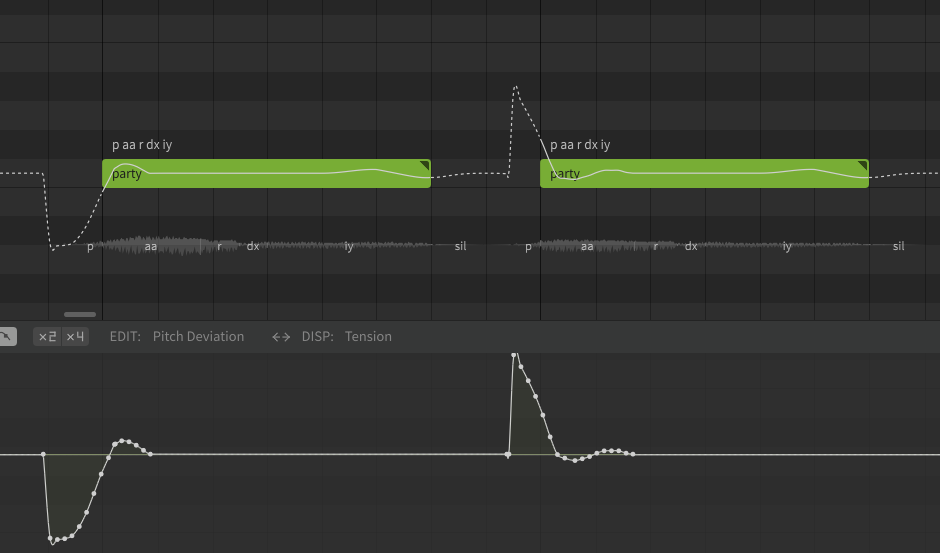
One of the most common examples of this in English is the use of the alveolar tap (dx) instead of a clear t sound, such as in the word "better", "party", and "water". The exact words that fit this pattern (or other similar patterns) will vary based on regional accent or dialect.
It is also common in many languages to substitute a variety of vowel sounds with a schwa (ax), or omit a vowel entirely. This can often reduce understandability if applied too liberally, but when used appropriately can result in more natural-sounding vocals.
English speakers will also often drop the final consonant of a word (usually the t from a word ending in "n't") and use a glottal stop ("ʔ", represented in Synthesizer V Studio as cl) to cut off the sound abruptly. This is most common with phrases like "donʔ do it" or "wouldnʔ you?" (though "wouldn't you" can sometimes also be shortened to "wouldn-tyu" or "wouldn-chu", which are all examples of connected speech as mentioned in the next section).
These are some examples of words that might sound overly formal or unusual if enunciated "properly":
| Word | Default Phoneme Sequence | "Lazy" Pronunciation |
|---|---|---|
| Camera | k ae m er ax | k ae m r ax |
| Don't → Don' | d ow n t | d ow n cl |
| Party | p aa r t iy | p aa r dx iy |
| Want To → "Wanna" | w aa n t / t uw | w aa n ax |
| "Wanna" | w aa n ax | w ax n ax |
Connected Speech
Connected speech behaviors, such as in the "want to" example above, are a major part of spoken (and sung) English. Understanding connected speech patterns can be very helpful in achieving your desired pronunciations.
Further reading: leonardoenglish.com
Disambiguating Similar Sounds
Unvoiced/Voiced Pairs
Most phonemes with similar mouth shapes are distinguished based on voicing (ie whether or not the vocal cords are engaged). For example, a k sound is just a g with no voicing. Often adjusting the voicing parameter can disambiguate similar sounds if they are not enunciated clearly, though this is rarely necessary.
These are some voiceless/voiced pairs used in Synthesizer V Studio's English phoneme set. Try making these sounds yourself and take note of the shape of your mouth, the airflow, and whether or not you engage the vocal cords when making each sound.
| Unvoiced | Voiced |
|---|---|
| t | d |
| th ("thing") | dh ("this") |
| k | g |
| s | z |
| p | b |
| f | v |
Pitch-affected Phonemes
Some phonemes can also sound different based on the pitch change over their duration. This is not common in English, however one example is with leading p and b sounds.
In addition to the difference in voicing, p is more often associated with a rising pitch, while a falling pitch can sound more like a b even if the sound is unvoiced.
Experiment with the pitch curve over the duration of the phoneme to make ambiguous sounds more clear. The exact result will likely vary based on the voice database used.
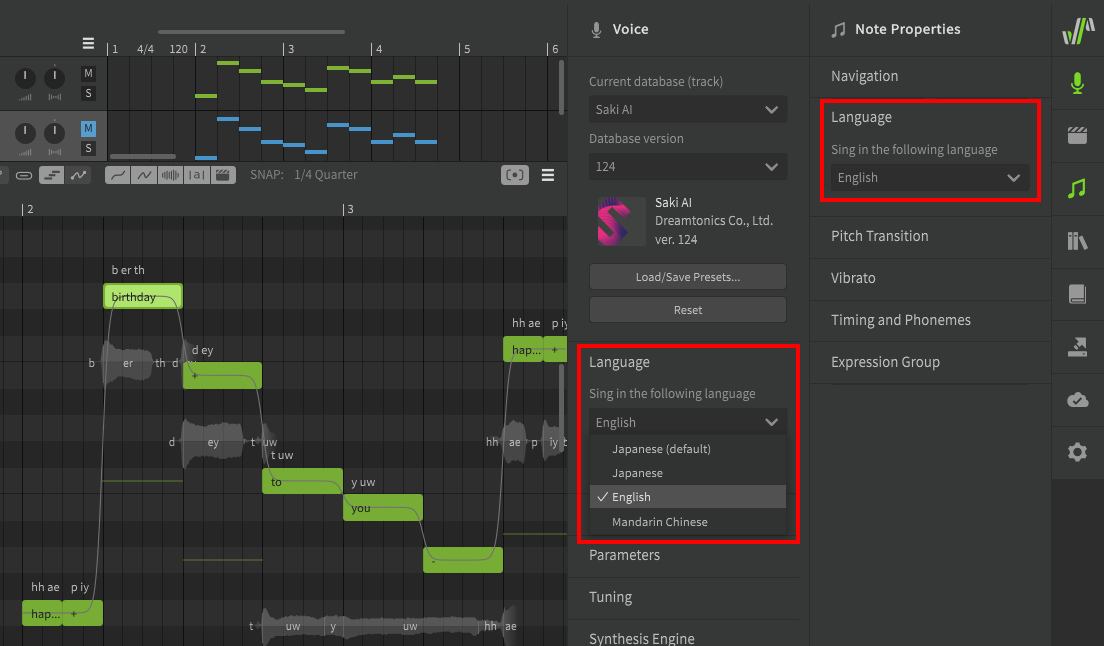
Cross-lingual Synthesis
Pro Feature
Cross-lingual Synthesis requires Synthesizer V Studio Pro.
Cross-lingual synthesis allows AI voice databases to access the phoneme lists for any supported language, regardless of the voice database's default language. While AI voice databases still have a "native" language, this allows them to sing lyrics in other languages with near-fluency.
Language settings can be found under the Voice and Note Properties panel, for the track/group and individual notes respectively.